Dieser Post ist Teil der Serie “Medizinische Datenformate”. Wie immer gilt: Kommentare, Korrekturen, Ergänzungen willkommen.
Keine Vorbedingung aber hilfreich:
- “Was ist eigentlich HL7”
- Was sind OIDs? (a.k.a.
1.2.276.0.76- das wirklich gern bitte lesen)
Legen wir los.
Überblick über die HL7 v3 Standards (mit Fokus auf CDA)
Noch einmal die Erinnerung: “HL7 v3” ist eine Gruppe an Standards. Sagt jemand allerdings “HL7 v3” meint diese Person meist den “Messaging” Teil aus der HL7 v3 Gesamtmenge. Ich versuche das wie erwähnt sauber zu trennen.
Die Gruppe an Standards, die zusammen HL7 v3 bilden, waren der designierte Nachfolger von HL7 v2, wobei die Ziele deutlich über die Ziele von HL7 v2 hinaus gehen.
- Start der Arbeiten 1995, erste Veröffentlichung 2005
- XML basiert, vollständig und absolut inkompatibel zu HL7 v2
- Formales Entwicklungsmodell, Ziel ist ein “gemeinsames Verständnis von Objekten und Prozessen”
- OIDs sind ein zentraler Bestandteil von allen HL7 v3 Standards (englische FAQ zum Thema “OIDs”, und hatte ich schon auf meinen mini-Artikel verwiesen? ;)
- Es gibt inhaltlich sowie technisch keinen Migrationspfad von v2 zu v3
- Der gesamte HL7 v3 Standard umfasst …
- ein Informationsmodell (“RIM”)
- eine Dokumenten-Spezifikation (“CDA”)
- und einen Messaging-Teil (HL7 v3, der inhaltliche Nachfolger von v2)
- sowie “unterstützende” (meine Bezeichnung) weitere Teile
Vorsicht, Meinung: HL7 v3 ist offenbar angetreten, sämtliche Aspekte medizinischer Interaktionen und Zusammenhänge in digitaler Form verlustfrei und rechtssicher (!) abbilden zu können. Ich werde mich im Folgenden sehr auf CDA konzentrieren, da es zum einen der spannendste, aber auch der relevanteste Teil der HL7 v3 Standards ist.
Vorneweg: Die standards aus HL7 v3 werden in der Praxis kaum genutzt. Das zu verstehen ist trotzdem interessant um das “digitale heute” besser einordnen und nachvollziehen zu können.
HL7 v3 RIM
- RIM = Reference Information Model
- Abstrakte Beschreibung von Datentypen (“Objekte”) und deren Beziehung untereinander
- Basis für die Objekte in CDA und HL7 v3 (Messaging)
- Aktuelle Version (Stand 2022-01-04): 2.47 vom 2021-12-10
Das HL7 RIM wurde entworfen um eine formatunabhängige Grundlage für zukünftige Standards zu haben. Es ist das abstrakte Datenmodell auf dessen Grundlage ein praktisch nutzbarer Standard entwickelt wird. Wer sich für detaillierte Hintergründe der Entwicklung interessiert wird bei ringholm.com fündig.
Ein Beispiel: Das RIM definiert konkret das Objekt “Person” als Spezialfall von “LivingSubject”, was wiederum eine Ableitung von “Entity” ist. Für jeden dieser drei Typen definiert es relevante Eigenschaften (zB Person: Adresse, Behinderungen, Rasse (ja, “RaceCode”); LivingSubject: Geburtsdatum, Organspende- und lebend/verstorben-Indikator; etc.). Für eine Implementierung muss man diese abstrakten Beziehungen und Eigenschaften jetzt in einer existierenden Beschreibungssprache (XML, JSON, YAML, …) modellieren. Ohne diesen Schritt ist es nur ein gedankliches Konstrukt.
Erwähnenswert ist dass das RIM publiziert wird im sog. “MIF” - dem “model interchange format”, für das es offenbar nicht eine einzige auffindbare Software zum Bearbeiten oder Darstellen gibt. (Ich nehme Tipps diesbezüglich (bevorzugt für Mac-Nutzer) sehr gern entgegen.) Einen Eindruck der Komplexität bekommt man über eine Google-Bildersuche nach “hl7 rim”.
Das deutsche HL7 Wiki formuliert zum Thema MIF folgendermaßen:
“Dies ist ein auf XMI aufbauendes Austauschformat, um Strukturbeschreibungen für die HL7 Version 3 Modelle zwischen den Anwendungen auszutauschen. Es dient aber auch als originäres Speicherformat, da XML-Schemas nicht ausreichen”.
Das HL7 RIM ist auch ein ISO Standard (ISO/HL7 21731:2014).
HL7 CDA
Im Zuge der Entwicklung der Standards aus HL7 v3 hat man sich auch Gedanken zu einem Dokumenten-Format gemacht, im Gegensatz zu HL7 v2 & v3, die eben besagen Nachrichten-Charakter haben.
- “HL7 Version 3 Clinical Document Architecture (HL7 v3 CDA)”
- 2 Releases (Release 1, November 2000 & Release 2, Mai 2005)
- Teil der HL7 v3 Standards, basiert auf dem HL7 v3 RIM
- Fokus auf Freitext-Informationen, strukturierte Daten optional
- CDA definiert ein Framework zur Erstellung digitaler medizinischer Dokumente
- CDA ist eine mögliche Implementierung von HL7 RIM auf XML Basis
Ein CDA Dokument ist die XML-basierte Repräsentation eines klinischen Dokuments (Arztbrief, Entlassbrief, Rezept, etc.). Die deutsche Anpassung des Standards hieß “Sciphox" und spezifiziert eine Basismenge an CDA-basierten Dokumenten für das deutsche Gesundheitswesen (siehe Link). Ein CDA Dokument liefert folgende Kerneigenschaften: Persistenz, verantwortliche Stelle, Signaturfähigkeit, Kontext, Ganzheit des Dokuments, Lesbarkeit.
Sog. “Level” beschreiben für jedes Dokument den Anteil der maschinenlesbaren Informationen. Erst Level 3 ist “strukturiert” in dem Sinne dass alle Informationen maschinenlesbar vorliegen. CDA legt also einen klaren Fokus auf die Freitext-Informationen, strukturierte Daten dienen immer nur als Ergänzung und sind grundsätzlich optional.
Die Strukturinformationen in einem Level 1 Dokument betreffen die Dokument-Metadaten (Ersteller, Dokumenttyp, etc.). Das eigentliche Dokument liegt entweder im sog. “narrativen Teil” als Freitext vor, oder es wird ein Binärdokument eingebettet (PDF, Bild, etc.). Level 2 fügt dieser Struktur “eine einheitliche strukturierte Beschreibung und Gliederung der Inhalte” hinzu, und erlaubt die Klassifizierung der Bestandteile durch Codesysteme wie SNOMED oder LOINC (mehr dazu in einem späteren Post). “Inoffiziell” werden die Level noch weiter unterteilt.
CDA-Dokumente bestehen grundsätzlich aus einem Header und einem Body. Der Header enthält die Informationen über Dokumenttyp, Patient, beteiligte Personen & sonstige Metadaten; der Body enthält dann die konkreten medizinischen Daten.
Eine zufällige Auswahl der Header-Elemente ist author, custodian, dataEnterer, recordTarget, participant.
Diese werden durch entsprechende Unterelemente ergänzt.
recordTarget zB enthält meistens einen Patient (ja, meistens).
Inhalte des narrativen Teils können mit Formatierungs-Informationen versehen werden, welche die Struktur der Darstellung bestimmen.
Diese bestehen aus HTML-ähnlichen Elementen (zB <list> statt <ul>/<ol>, <paragraph> statt <p>, etc.).
Das konkrete Aussehen bei einer Darstellung soll dann über Stylesheets geregelt werden.
Die Stylesheets werden dabei von den Implementierern entworfen und sind nicht Teil des Standards.
Eine zufällige Auswahl der Body-Elemente (also die optionalen strukturierten Daten) ist Observation, SubstanceAdministration, Supply, Encounter, Act, Procedure.

Für alle fachlichen Elemente können noch Attribute definiert werden.
Klassisches Beispiel:
Das erwähnte Patient-Element hat ein birthTime-Attribut.
Diese Attribute bestehen aus wiederverwendbaren Datentypen, im konkreten Fall aus dem Typ “TS” (“Point in time”).
Der Datentyp “IVL” aus der abgebildeten “Act” Klasse steht für “Interval”.
So langsam sollte der Eindruck einer gewissen Komplexität entstehen.
Kurz mal den Zeh ins Technische halten
Wie erwähnt bestehen CDA-Dokumente aus einem Header und einem Body.
Hier eine grafische Repräsentation der Struktur eines CDA Dokuments.
Grob sind “rechts” sind die “Body” Elemente, die Elemente “links” werden im Header verwendet.
Die “Insel” in der Mitte enthält noch das Element NonXMLBody, was für eingebettete Binärdaten (zB PDF Dokumente) verwendet wird.
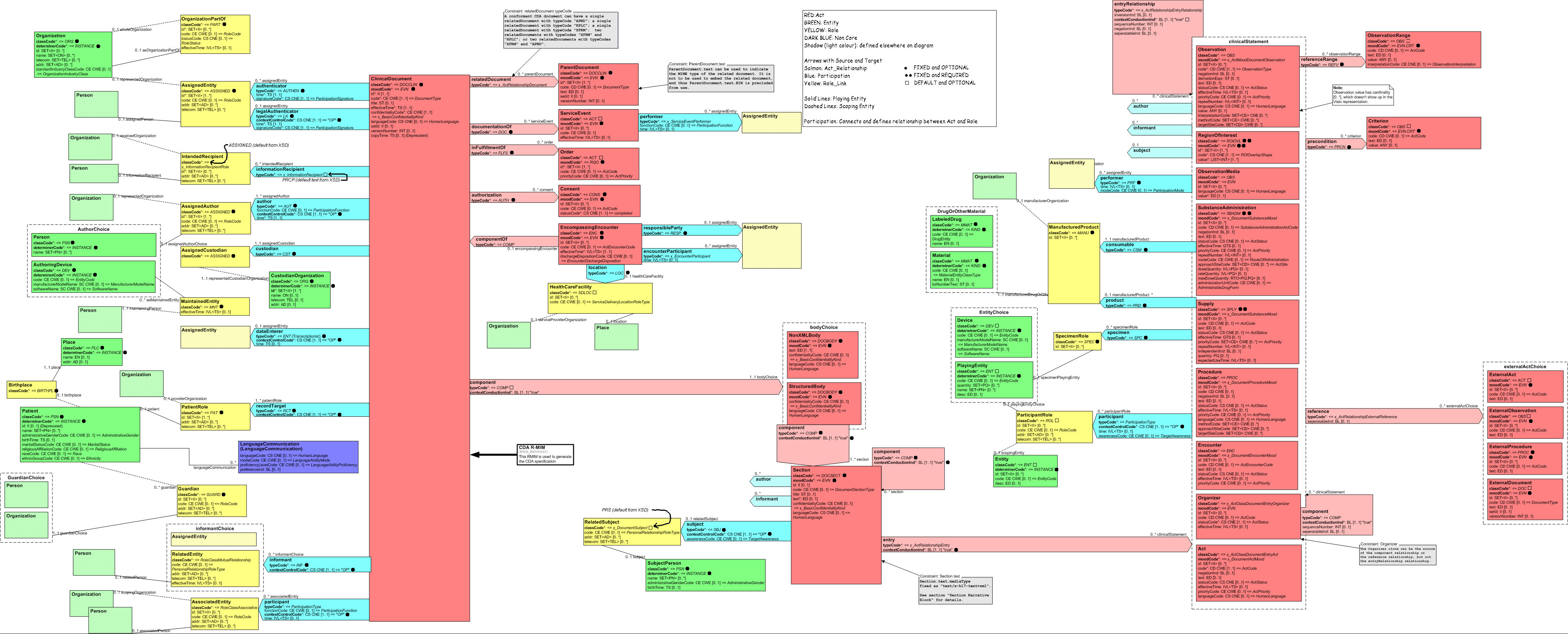
Jetzt haben wir die Elemente aus dem RIM, allgemeine Datentypen für … allgemeine Informationen, und ein Schema wie ein CDA Dokument aufgebaut ist. All das zusammen ergibt jetzt folgenden schematischen Aufbau eines Dokuments. Im Folgenden ein extrem reduziertes Beispiel, um den Aufbau zu verdeutlichen. Das komplette beispiel ist auf GitHub zu finden.
Diese langen Zahlenketten (zB 2.16.840.1.113883.6.96) sind sog. “OIDs”, die bezeichnen weltweit eindeutig “Dinge”.
Wenn man das einfach so hinnehmen kann super, wenn man allerdings schon hier angekommen ist empfehle ich dringend nochmal meinen “Was sind OIDs?” mini-Artikel. Er ist auch wirklich kurz und prägnant.
<ClinicalDocument xmlns="urn:hl7-org:v3" xmlns:voc="urn:hl7-org:v3/voc"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<!-- CDA Header, ausgelassen, da zu groß -->
<!-- CDA Body -->
<component>
<structuredBody>
<component>
<!-- this describes a plan of treatment. full example here: https://is.gd/Aw15f8 -->
<section>
<templateId root="2.16.840.1.113883.10.20.22.2.10" extension="2014-06-09" />
<code code="18776-5" codeSystem="2.16.840.1.113883.6.1" codeSystemName="LOINC" displayName="Treatment plan" />
<title><text>this is the narrative part, NON OPTIONAL</text></title>
<!-- "entry" is the structured part, optional -->
<entry>
<procedure moodCode="RQO" classCode="PROC">
<templateId root="2.16.840.1.113883.10.20.22.4.41" extension="2014-06-09"/>
<id root="9a6d1bac-17d3-4195-89c4-1121bc809b5a"/>
<code code="73761001" codeSystem="2.16.840.1.113883.6.96" codeSystemName="SNOMED CT" displayName="Colonoscopy"/>
<statusCode code="new"/>
<effectiveTime><center value="20120512"/></effectiveTime>
<author><!-- blablabla --></author>
</procedure>
</entry>
</section>
</component>
</structuredBody>
</component>
</ClinicalDocument>
Wir können jetzt zwar alles ausdrücken, verstehen aber nichts
OIDs ermöglichen es uns, auf jedes beliebige existierende System der Welt zurückzugreifen um damit die Dinge auszudrücken, die wir möchten. Das ist zwar formal genial, praktisch allerdings ein Problem. Es wird vllt mit einem Beispiel einfacher.
<value xsi:type="CD" code="A05.1" codeSystem="1.2.276.0.76.5.413" displayName="Botulismus">
<qualifier>
<name code="8" codeSystem="2.16.840.1.113883.3.7.1.0"/>
<value code="V" codeSystem="1.2.276.0.76.3.1.1.5.1.21"/>
</qualifier>
</value>
Nehmen wir das auseinander.
- Das
value-Element codiert “Botulismus” (A05.1) in “ICD-10 GM, Version 2013” - Ein
qualifierbedeutet erst einmal “Ergänzung”. Für Details schauen wir uns die Kind-Elemente an.namedefiniert incodeSystemdie OID für das deutsche Sciphox. In dieser spezifischen Erweiterung ist Code “8” definiert als “Zusatzkennzeichen zur Diagnose”.valuebringt nun ein solchen Zusatzkennzeichen ein, und zwar über die OID einer speziellen KBV-Erweiterung. Diese definiert “V” als “Verdacht auf”.
Wir haben also einen “Verdacht auf Botulismus”.
Ja, das ist schon sehr krass.
Jetzt kommt der Witz: Man kann diesen qualifier allerdings auch ohne jeden Informationsverlust so ausdrücken:
<qualifier>
<name code="FSTAT" codeSystem="1.2.276.0.76.3.1.195.5.72" displayName="Befundstatus"/>
<value code="SUSP" codeSystem="1.2.276.0.76.3.1.195.5.73" displayName="Verdacht"/>
</qualifier>
Das transportiert exakt dieselbe Information!
Nur jetzt werden in den codeSystems vom DIMDI verwaltete Teilbäume referenziert, die “Elementtypen” und “Befundstatus” definieren.
Noch Fragen? Keine? Gut.
Interoperabilität durch Templates
Das Beispiel macht sehr deutlich, dass “CDA” alleine keineswegs bedeutet, dass Systeme interoperabel sind. Wenn System 1 Beispiel 1 schickt (ICD10-basiert), System 2 aber Beispiel 2 erwartet (ein braves deutsches DIMDI-System) - dann wurde die Information zwar vollkommen korrekt übertragen, es wird allerdings kein Verständnis erzielt.
Dieses Problem lösen CDA Templates. Jedes Dokument spezifiziert eine Template ID, und das Template gibt Art, Struktur und verwendeten Codesysteme des Dokuments vor. Unterstützen also zwei Systeme die gleichen Templates sind sie interoperabel. Templates sollten über die Website art-decor.org verwaltet und veröffentlicht werden.
<observation classCode="OBS" moodCode="EVN">
<templateId root="1.2.276.0.76.10.4049"/>
<!-- ... -->
<value xsi:type="CD" code="A05.1" codeSystem="1.2.276.0.76.5.413" displayName="Botulismus">
<qualifier>
<name code="8" codeSystem="2.16.840.1.113883.3.7.1.0"/>
<!-- etc. -->
Das Template liefert jetzt alles was man braucht (zumindest theoretisch), um ein CDA Dokument erzeugen und verarbeiten zu können. Wichtig zu verstehen ist hier allerdings, dass ein Template den Prozess nicht einfacher, sondern möglich machen soll.
Eine Sammlung von CDA-Beispiel-Dokumenten findet man in einem GitHub Repository, und es existiert ebenfalls ein Web Frontent.
HL7 v3 (“Messaging”)
Der Messaging-Teil aus HL7 v3 ist von der Zielsetzung her identisch zu HL7 v2, und war als dessen Nachfolger gedacht.
- Löst HL7 v2 ab mit den Prinzipien die allen Standards aus HL7 v3 zugrunde liegen
- RIM-basiert, XML, formales Entwicklungsmodell, etc.
- Nur ein Teil der Gesamtmenge aller HL7 v3 Standards
- Datenstrukturen analog von HL7 CDA
Ich schreibe weiter oben “‘war’ der Nachfolger”, weil ich keine Anwendungen von HL7 v3 gefunden habe. Der Standard hat meines Erachtens heute zumindest in Deutschland keine Relevanz. Eventuell konnte auch einfach niemand das MIF lesen … .
(fairerweise: das RIM-Archiv 2.47 / Release 7 auf der HL7-RIM-Seite enthält auch einen Satz verwaschener GIF Bilder die man zu Rate ziehen kann. Das nur am Rande.)
Akzeptanz & so eine Art “Fazit”
Bei der Akzeptanz muss man trennen zwische HL7 v3 Messaging und CDA.
Messaging: Ganz platt formuliert - keine. Eine ganze Industrie weigert sich.
CDA: begrenzter Erfolg in Nischenprozessen. Der Verband der gesetzlichen Unfallversicherungen (DGUV) nimmt zB Entlassbriefe als CDA an (ob das verpflichtend ist weiß ich nicht).
Das klingt jetzt erst mal ganz gut. Dann realisiert man, dass dieser Entlassbrief ausschließlich dann verarbeitet werden kann, wenn man das zugehörige Template unterstützt. Derselbe Entlassbrief kann so nicht in die elektronische Patientenakte eines Patienten geschrieben werden. Dazu müsste man ein (hypothetisches) weiteres CDA Template unterstützen. Und damit haben wir die Erzeugung abgehakt, und - je nach technischem Unterbau - noch nicht das Einlesen dieser Entlassbriefe (falls man das möchte). Ach ja, und mit all den Metadaten muss das Dokument trotzdem unter einem bestimmten Dateinamen abgelegt werden (Techn. Dokumentation, Kap. 3.2).
Randbemerkung: Ob sich überhaupt ein “allgemeingültiger” Entlassbrief (oder jegliches medizinisches “Ding”) formulieren lässt ist in der Tat eine extrem spannende Frage.
Trotzdem hat mir persönlich diese Zusammenstellung viel Spaß gemacht, irgendwie. Warum?
- Wenn man das alles weiß, dann sieht man FHIR (nächster Post :) mit ganz anderen Augen.
- Hier haben sehr viele teils sehr kluge Menschen versucht, im Wortsinne “alle möglichen” Fälle zu durchdenken und aufzuschreiben. Dass “triviale” Dinge wie “Wer ist der Autor eines Dokuments” kompliziert sein können (ggf. wenn man sie lässt) ist schon eine Erkenntnis.
- Das Level an Formalität in der HL7 v3 Menge ist … “krass”.
Ein paar Eindrücke:
- CDA hat 61 “Implementation Guides”, und eine “navigation website”
- es gibt ein Dokument mit 247 Seiten, was laien-verständliche Formulierungen für medizinische Begriffe vorschlägt, die man in User Interfaces verwenden kann. Für “diuretic” wird “drug that makes you pee more” vorgeschlagen.
- Das erhoffte Meer aus XML-Daten wollte man jetzt befahren mit der Arche GELLO. Das ist ein eigens entwickelte “Common Expression Language” für Abfragen und Datenmanipulation. Grundlage dafür war OCL (die “Object Constraint Language”), entwickelt von der OMG (Object Management Group).
- Es gibt 12 verschiedene Möglichkeiten “ich habe diese Information nicht” digital auszudrücken.